
Кей Колектор: інструкція по роботі та налаштування програми
Доброго часу доби, шановні читачі блогу iklife.
Сьогодні я вирішив вам розповісти про програму Кей Колектор. Дуже відома і функціональна утиліта, яка застосовується при складанні семантичного ядра для SEO-просування і контекстної реклами.
Найчастіше Key Collector використовується веб-майстрами і СЕО-фахівцями, але не всі знають, як його правильно налаштувати. У цьому матеріалі я наведу вам докладну інструкцію по налаштуванню цього додатка.
Зміст
- Що таке Key Collector?
- Інструкція по роботі та налаштування
- Загальні
- Yandex.Wordstat
- Пошукова видача та підказки
- KEI & SERP
- Антикапча
- Регіони
- Стоп-слова
- Збір семантики
- Частотність
- Сезонність
- Інші пошукові системи і рекламні мережі
- Висновок
Що таке Key Collector?
Кей Колектор – це платна утиліта, яка повсюдно використовується сеошниками і маркетологами. Суть її полягає у майже повній автоматизації збору семантичного ядра. Програма тісно інтегрована з Яндекс Діректом, Вордстатом, гугловський сервісами та іншими інструментами, які поодинці не виглядають такими практичними.
Тобто Key Collector поєднує в собі кілька сервісів, інтегруючи їх можливості. Це дозволяє людям легко і просто парсити запити з того ж Вордстата або Діректа, надалі перетворюючи їх у цілком обґрунтоване семантичне ядро.

Як я вже сказав, щоб користуватися програмою, її доведеться купити. Розробники дуже сильно піклуються про збереження ліцензії, тому кожна окрема програма прив’язується до одного персонального комп’ютера за допомогою ідентифікатора жорсткого диска. Отже, ви не зможете скачати додаток, щоб використовувати його на декількох машинах – 1 ліцензія для 1 комп’ютера.
В інтернеті, звичайно, є зламані версії, які нібито надають ті ж можливості, що і оригінал. Однак варто враховувати, що через піратське ПО дуже часто поширюються віруси. Якщо вже ви не хочете купувати Колектор, то я б рекомендував вам звернути увагу на СловоЕб. Це безкоштовний додаток від тих же розробників, яке являє собою спрощений варіант Колектора.
Тепер давайте більш детально розглянемо можливості програми. Отже, як заявляють розробники, з допомогою Key Collector ми зможемо скласти більш точне семантичне ядро, не вдаючись до допомоги сторонніх фахівців. Нам лише потрібно правильно налаштувати всі параметри і пізнати деякі ази.

Треба сказати, що Key Collector не працює з готовими базами даних, які вимагають постійні оновлення. Він парсити всю інформацію в реальному часі через інтернет, підключаючись до все тим же сервісів: Вордстат, Яндекс Директ, Гугл Адвордс та іншим. Такий підхід гарантує вам актуальність всіх ключів, які ви отримаєте на виході.
Ця програма допоможе вам побачити найбільш популярні сторінки вашого сайту, визначити вірну стратегію просування, грунтуючись на статистичних даних. В кінцевому підсумку ви можете вивантажити всю інформацію в зручний формат, наприклад, в таблицю Excel.
Я впевнений, що купити програму безперечно варто. Якщо зрозуміти, як працювати, то це може заощадити істотну частину фінансів і часу. Так і проекти з якісною семантикою будуть давати більше віддачі, що також є плюсом.
Інструкція по роботі та налаштування
Загальні
Щоб відкрити головне вікно налаштувань, перейдіть в “Настройки” – “Парсинг” – “Загальні”. Саме там ви побачите основні параметри програми, які при необхідності можна легко змінити.
За замовчуванням там все і так грамотно налаштований, тому можна, в принципі, їх і не чіпати. Але якщо ви хочете оптимізувати роботу програми, то я пропоную вам використовувати такий варіант.


Звертаю вашу увагу на пункт “Кількість повторних спроб…” Буде розумніше збільшити значення до 30 – 90, щоб у разі якихось непередбачених обставин програма могла сама відновлювати роботу. Це актуально і для тих користувачів, які будуть працювати з десятками тисяч різних запитів, при збоях мережі або якихось інших негараздах.
Yandex.Wordstat
Зараз Яндекс Вордстат дуже посилює правила роботи. Він не дуже любить Кей Колектор, тому використання такого або будь-якого софту може прирівнюватися до порушення правил.
Якщо раніше парсинг з Вордстата був можливий і без реєстрації аккаунта, то тепер доведеться витратити кілька хвилин для створення нової пошти на Яндексі. Якщо ви вирішите прикрутити до Колектора свій основний рахунок, то швидше за все його рано чи пізно забанять.
Створюємо один або декілька облікових записів Яндекс, йдемо в “Парсинг” – “Yandex.Direct”. Там ми повинні вписати логіни і паролі облікових записів – кожен з нової строчки.
Тобто це буде виглядати так: Логін:Пароль – саме через двокрапку і без пробілу.

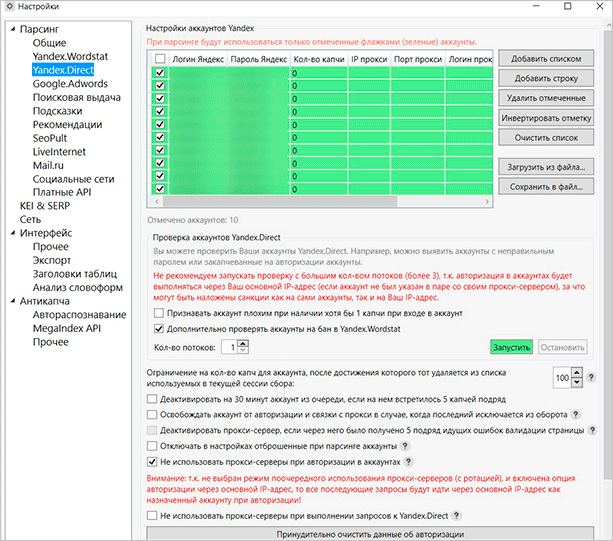
Кожну пару Логін:Пароль ми прописуємо з нової строчки. Врахуйте, що якщо ви вирішите вказати кілька десятків аккаунтів, сподіваючись тим самим підвищити продуктивність роботи програми, – вас чекає фіаско. При кожному запуску Колектор авторизується до всіх облікових послідовно. Якщо їх буде занадто багато, то відповідно й часу на остаточний запуск і завантаження буде вимагатися більше.
І врахуйте, в якості логіна треба вписувати саме його, а не поштову адресу. Тобто якщо ви зареєстрували [email protected], то у віконці налаштувань буде тільки – textfree.
Тепер ми перейдемо до налаштування самого Вордстата. Для цього в “Парсингу” знаходимо вкладку “Yandex.Wordstat”.
Тут представлено дуже багато різних налаштувань. Всі їх можна при бажанні поміняти, але стандартна конфігурація також може непогано працювати. На скріншоті нижче представлений непоганий варіант опцій, який можна використовувати для роботи з семантикою.

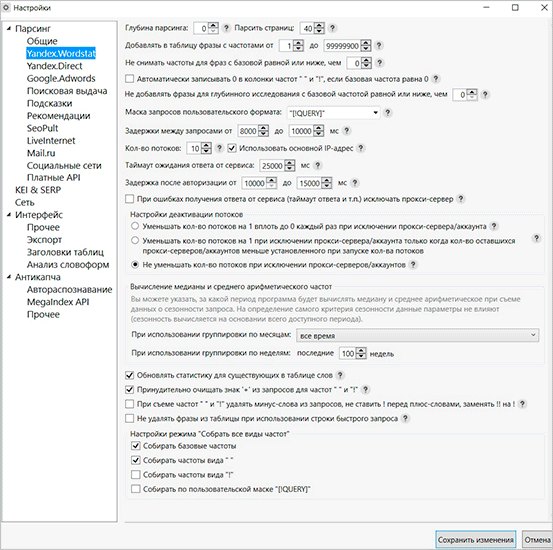
Будь-які масштабні зміни необхідні лише у випадку тонкого складання ядра з урахуванням якихось особливих параметрів. Опцію “Глибина парсинга” розробники рекомендують не чіпати – тобто залишити значення 0.
Також варто врахувати ймовірність бана по IP. Щоб уникнути цього, ставте тільки 1 потік на 1 IP-адресу. І не забувайте про частоту між запитами, рекомендується встановити значення в межах 20 – 25 000 мс.
Щоб не мучити себе обмеженнями, ви можете використовувати проксі-сервера. В тій же вкладці Yandex.Direct (там, де ми вводили дані від аккаунта) тепер потрібно вказати трохи іншу інформацію.
Тепер це буде виглядати так:
#ІРПрокси:Порт:ЛогинПрокси:ПарольПрокси:ЛогинЯндекса:ПарольЯндекса
Сітка (#) на початку кожного рядка обов’язкове. Це потрібно, щоб проксі використовувалося в будь-якому випадку з якимись окремими записами. При відсутності символи до початку рядка будуть потрібні додаткові налаштування проксі в розділі налаштувань – “Мережа”.

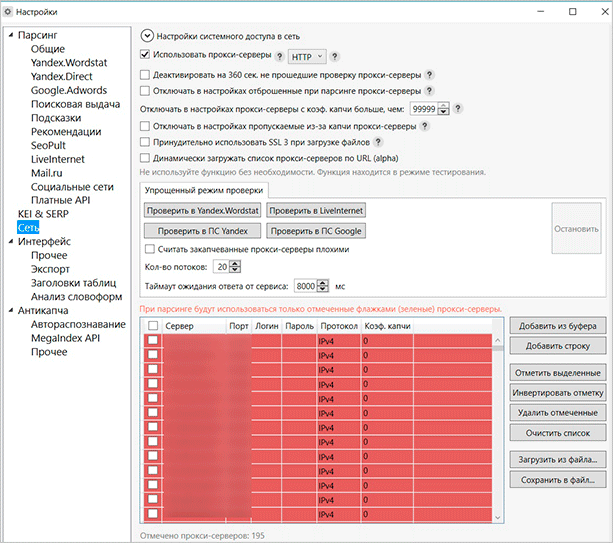
Ви можете використовувати розділ “Мережа” для вказівки статичних даних авторизації для проксі-серверів. Іншими словами, ви повинні вписати всі ті ж логін і пароль від проксі, але тепер вони будуть використовуватися для всіх акаунтів.
Другий спосіб може бути актуальним для не дуже якісних проксі-серверів. Він все так само обмежений одним потоком на один проксі-сервер. Однак у випадку бану, ви вже не так сильно постраждаєте – можна буде просто розірвати авторизацію і виконати її заново.
Там же, в налаштуваннях мережі, ви можете вибрати додаткові параметри використання проксі-серверів.
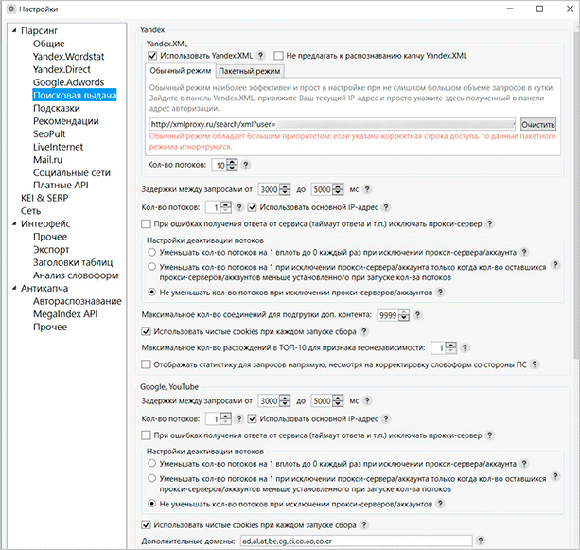
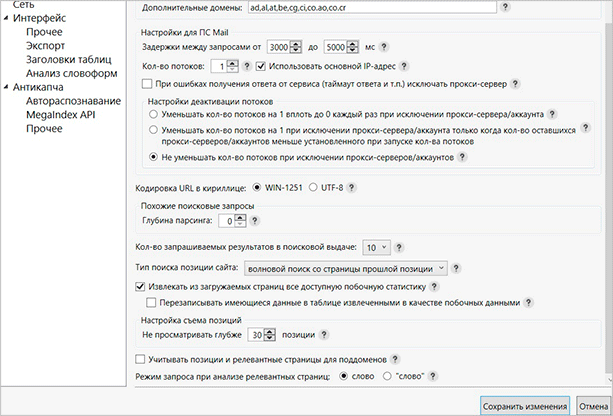
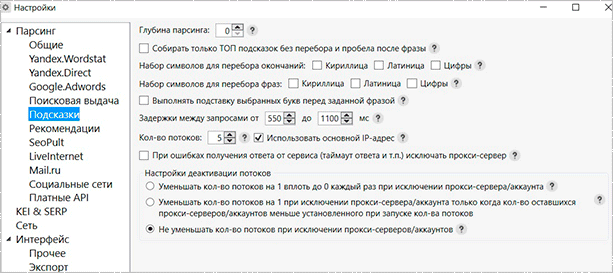
Пошукова видача та підказки
Для правильної установки програми вам доведеться приділити увагу пошуковій видачі і підказок. Нижче я представлю кілька скріншотів з одним з вірних варіантів налаштувань. Ви можете скопіювати їх собі.



KEI & SERP
З допомогою формул KEI ви зможете легко виключити з загальної таблиці не релевантні запити – ті, які не принесуть користі. Вам потрібно буде створити формулу розрахунку і записати її в одне з вікон.

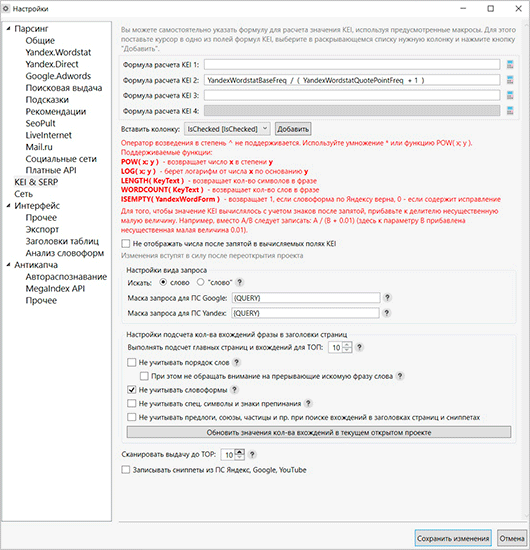
Як правило, КЕІ розраховується з відношення базової частотності до частотності в точній входження +1. Досвідчені фахівці можуть використовувати і інші формули для пошуку непотрібних запитів.
Антикапча
Якщо ви не хочете кожен раз вручну розгадувати символи, які прилітають до вас при роботі програми, то я рекомендую вам звернути увагу на сервіси антикапчи. Key Collector підтримує інтеграцію з ними, тому вам достатньо просто зареєструватися, сплатити передплату і налаштувати антикапчу в додатку.
Щоб зробити це, йдемо у вкладку “Антикапча”. Там ми побачимо поля з інформацією, яку можна отримати в будь-якому російськомовному сервісі розпізнавання капчі. Наприклад, Anti-Captcha або RuCaptcha.


Після реєстрації на сервісі розпізнавання капчі, ви отримаєте ключ – треба вставити у відповідне вікно, наприклад, в RuCaptcha Key. Зберігаємо зміни. Тепер введення символів буде відбуватися в автоматичному режимі.
Регіони
При роботі з парсером Вордстат у вас може з’явитися необхідність поставити якийсь конкретний регіон. Програма підтримує всі регіони, які релевантні для самого Yandex.Wordstat.
У нижній частині додатка знаходимо однойменну кнопку.


Далі відкриється вікно вибору регіону. Там ми можемо вибрати як один, так і декілька областей, за якими буде здійснюватися збір семантичного ядра.

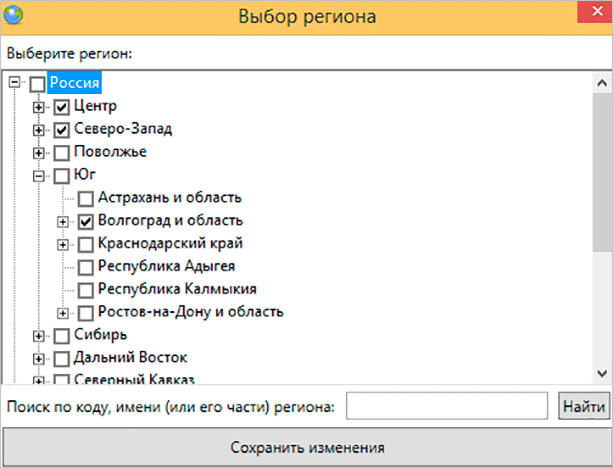
Тут є дуже багато різних регіонів, які можна поєднувати, так і вибрати якийсь окремий.
Не забувайте, що налаштування регіону зберігається тільки в файлі проекту, який ви створюєте. Якщо ви вирішите попрацювати над новим проектом, то все зіб’ється. Будьте уважні з цим питанням, не допускайте помилок.
Стоп-слова
За допомогою стоп-слів ви зможете задати небажані фрази і слова, які будуть ігноруватися при вибірці. Це може істотно скоротити час збору семантики, особливо якщо ви зможете правильно визначити ці стоп-слова.

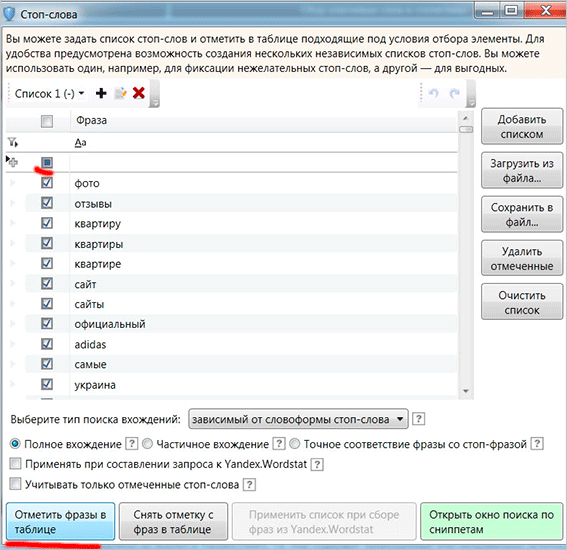
Не забувайте, що велика кількість стоп-слів також може мати негативний вплив на роботу програми. У Вордстаті є деяке обмеження на кількість символів в запиті. Це означає, що при подставлении великої кількості стоп-слів, програма не буде працювати коректно.
Збір семантики
Ось ми й перейшли до найсмачнішого. Збирати ключі можна з лівої і правої колонок Вордстата. Як ви напевно знаєте, в лівій показуються запити з входженням ключового слова. В правій же – схожі запити.


У цьому матеріалі ми розглянемо саме збір з лівої колонки. Отже, натискаємо на червону кнопку, після чого у нас відкривається таке вікно.

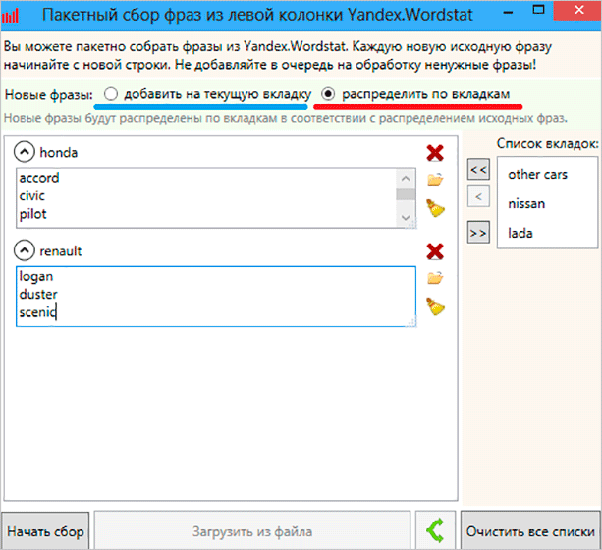
Тут ми можемо ввести ключові слова, які нам потрібні. Їх можна розбити на вкладки та групи. Ключі можна вводити вручну, а можна просто завантажити з файлу.
Після натискання кнопки “Почати збір” програма почне свою роботу. В залежності від налаштувань і кількості ключів цей процес може зайняти певний час. Іноді і по кілька годин. В кінцевому підсумку ви отримаєте список всіх ключових слів і фраз з лівої колонки Вордстата.
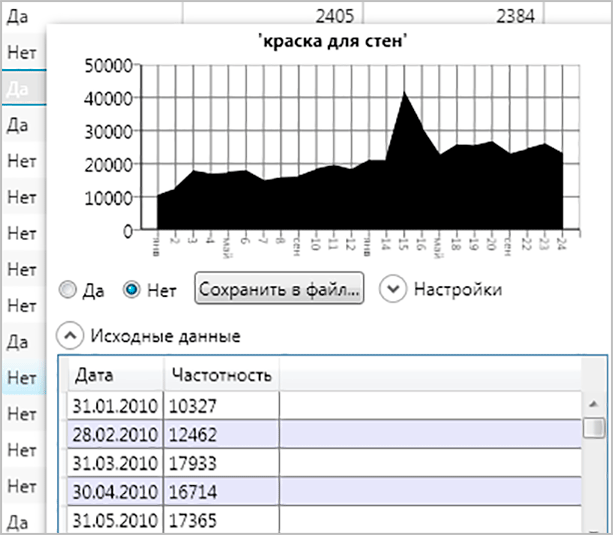
Далі ми можемо зняти більш точну частотність, бо як та, що буде доступна відразу після збору, – помилкова. Не варто їй довіряти і вже тим більше робити якісь висновки.
При зборі з правої колонки порядок дій той самий. Тільки ключів вийде більше, в силу того, що в таблицю потраплять всі “схожі”.
Частотність
Після збору самої семантики, ви можете зібрати частотність. Причому базова частотність не дасть нам особливо корисної інформації, тому нас цікавить частотності з входженням конкретних слів (” “) і з точним входженням (“!”)
Для збору всіх видів частотностей ми можемо використовувати одну кнопку.

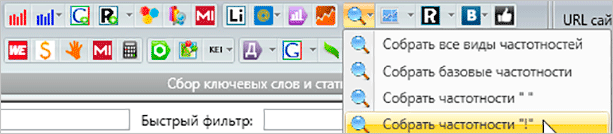
Знімання більш точних частотностей дозволить вам отримати найбільш правильні статистичні дані про кількість запитів у Яндексі. Базова варіація не відображає справжню суть, і найчастіше при складанні семантичного ядра вона ігнорується.

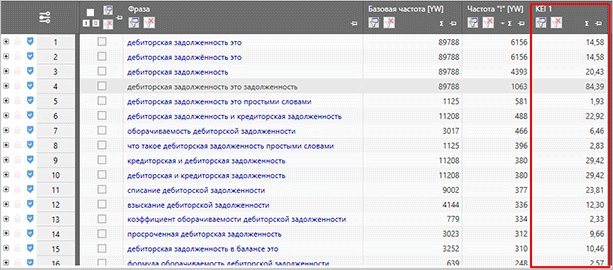
Саме збір частотності в кінцевому підсумку дозволяє вам кластеризовать семантичне ядро по запитам: ВЧ, СЧ і НЧ. Виходячи з цих даних, сеошники можуть розділяти ключі за групами, створюючи для кожної окремої статті свою невелику базу з тайтла і декількох ключових слів. Далі ця інформація передається копірайтерам для написання статей. Зараз такий спосіб є найбільш популярним при роботі з інформаційними сайтами.
Сезонність
Сезонні запити – це ключі, які актуальні в певний час року чи у якийсь конкретний час. Якщо ви збираєте семантику для магазину з пляжними товарами, то вам потрібно брати в розрахунок найбільший попит, а саме в літній час.
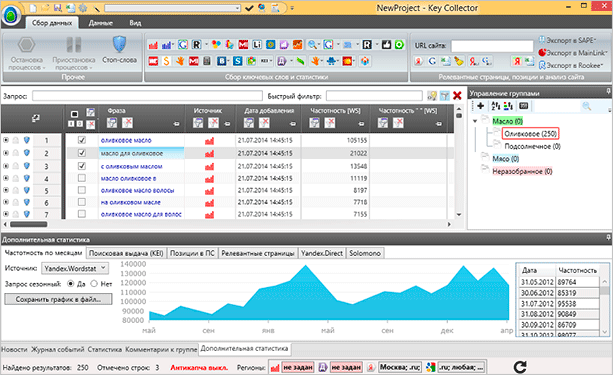
Збір сезонності дозволить вам визначити, які запити в який час користуються найбільшою популярністю. Щоб зібрати цю інформацію з допомогою Кей Колектора, знайдіть в меню іконок кнопку “Збір ключових слів і статистики”.

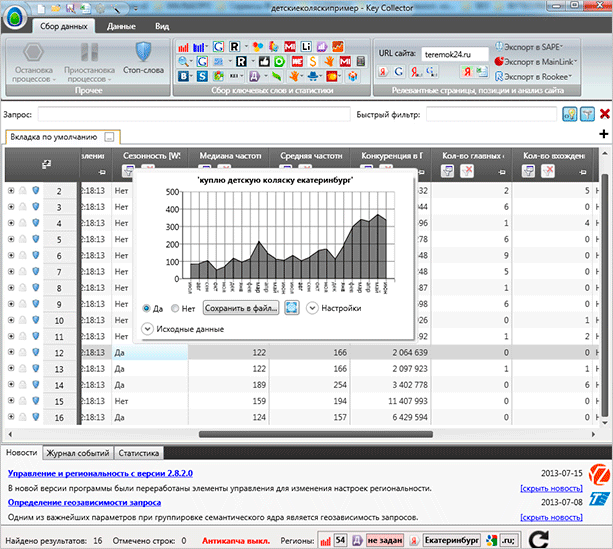
Після завершення процесу на прикладі графіка ви зможете побачити популярність того чи іншого запиту в якийсь конкретний місяць.

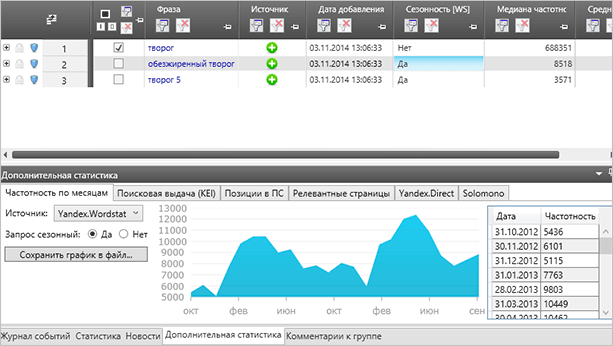
Ви можете отримати дані по тижнях, а не по місяцях, як це показано на скріншоті. Для налаштування використовуйте ту ж кнопку “Збір ключових слів і статистики”, вона розкривається, там ви знайдете відповідний пункт.
При необхідності ви можете переглянути більш детальну інформацію. Для цього просто клацніть на потрібній комірці.
Інші пошукові системи і рекламні мережі
У цій статті я розглядав найбільш популярну область застосування Колектора – парсинг з Yandex.Wordstat. Якщо ви хочете використовувати це додаток для збору семантичного ядра з якихось інших пошукових систем або рекламних мереж, то вам також доведеться налаштовувати кожен окремий пункт.
Можливо, в майбутньому з’явиться окрема стаття про детальної настройки кожного пункту цієї чудової утиліти, але якщо вам несила, то ви можете скористатися офіційним мануалом від розробників. У ньому досить докладно розглядаються аспекти налаштування Adstat Rambler, LiveInternet, Google AdWords та інших. Обов’язково ознайомтеся з поданим матеріалом.
Висновок
Key Collector – складна, багатофункціональна утиліта, яку ось так от просто не освоїти. Для більш повного розуміння найчастіше проходять спеціальне навчання. На курсах отримують уроки по роботі з семантикою та навички по Кей Колектору або аналогам. Тому відразу вивчити цю програму повністю не вийде.


Необхідний мінімум у цій невеликій статті я вам дав. За допомогою модуля Яндекс Вордстат ви зможете здійснювати знімання семантичного ядра, одержувати всі види частотностей і використовувати це для складання крутих матеріалів. Майте на увазі, що збір семантичного ядра – робота важка. Вона вимагає серйозного підходу, і жоден інструмент не буде робити за вас абсолютно всю роботу.
У випадку з Кей Колектором вам точно доведеться покопатися з налаштуваннями. Багато користувачі спочатку приділяють не так багато часу, за що згодом розплачуються неправильно складеної семантикою. Не робіть помилок, намагайтеся приділити належну увагу налаштувань і вивчення особливостей роботи цієї утиліти.
Якщо ви хочете розбиратися не тільки в зборі семантичного ядра, але ще й у створенні крутих сайтів і їх монетизації, я можу запропонувати вам пройти курс Василя Блінова “Як створити блог”. У ньому будуть розглянуті всі нюанси роботи вебмайстра, в тому числі і такого аспекту, як збір семантичного ядра. По програмі Key Collector ви теж пройдетеся, отримавши більш повні знання про роботу в ньому. Доступ на перший рівень надається абсолютно безкоштовно, тому не пропустіть свій шанс.