
Як правильно скласти семантичне ядро – збір і групування ключових слів
Вітаю, дорогі сеошники!
Сьогодні я вирішив розібрати дуже важливу тему. Ми будемо говорити про те, як правильно скласти семантичне ядро самому, розбити його по групам, а також очистити від зайвих валідних запитів. Якщо ви хочете більш докладно дізнатися про те, що таке семантичне ядро, то милості прошу в матеріал, який доступний за наведеним посиланням.
Зміст
- Семантичне ядро простими словами
- Способи складання семантичного ядра
- Key Collector
- Яндекс Вордстат
- Яндекс Вордстат + СловоЕБ
- Онлайн-сервіси
- Замовлення у фахівця
- Варто складати семантику?
- Як правильно скласти семантичне ядро по кроках?
- Збір первинних ключів
- Парсинг базових запитів за допомогою СловоЕБа/Кей Колектора
- Отримання цієї частотності
- Кластеризація запитів
- Пошук хвостів
- Висновок
Семантичне ядро простими словами
Семантичне ядро – слова і словотвору, які ототожнюють тематику вашого сайту. Як правило, воно являє собою збірник ключевіков, які ви повинні будете використовувати при наповненні ресурсу. Далі файл з цими ключами передається людині, яка займається формуванням технічних завдань. Завершують цю ланцюжок копірайтери, які грамотно розставляють ключові слова і фрази в статтях.
Для комерційних сайтів дана ланцюжок також майже нічим не відрізняється, за тим лише винятком, що ключові слова і фрази використовуються в статичних елементах ресурсу, описах товарів і послуг, а також інших сторінках з інформацією.
В обох випадках ці ключевики прописуються в мета-тегах сайту. Це одна з обов’язкових умов грамотного пошукового просування веб-ресурсу.
Напевно ви вже здогадалися, що ці слова і фрази залежать від того, що шукають користувачі в пошукових системах. Тобто якщо як приклад взяти запити “купити гарний диван” і “магазини диванів”, то можна прикинути, що по одному з них частота буде вище. Відповідно в інтернет-магазині з диванами потрібно буде вказати ключ “Купити гарний диван”, щоб пошукова система додала видачу ваш ресурс за цим запитом.
Семантичне ядро або семантика – це список, що складається з великої кількості таких запитів, який, як правило, згрупований за певним типом. Таке явище ще називають кластеризацией і майже у всіх випадках фахівці вдаються до використання. Це допомагає не тільки скласти грамотний план виписки текстів, але і визначити, з яких саме типів пошукових запитів буде здійснюватися просування.
Способи складання семантичного ядра
Key Collector
Для складання семантики ми можемо скористатися програмами для створення СЯ. Якісь з них роблять майже всю роботу за вас – їх ще називають автоматичними. У якихось сервісах доведеться більше працювати самостійно.
Наприклад, є така платна утиліта Key Collector. Хоча в ній цей процес майже повністю автоматизований, необхідно знати, як налаштувати Key Collector. На виході вам лише залишається трохи прибратися в запитах, прибравши звідти найбільш даремні, що включає в себе запити від роботів, спам і т. д. Вартість такої програми становить майже 2 000 рублів.
Яндекс Вордстат
Займатися збором семантики можна і за допомогою сервісу від Яндекса – Вордстат. Їм дуже легко користуватися, досить просто ввести ключове слово, він виведе вам запити, в яких присутній даний ключ. Разом з цим Wordstat покаже вам і схожі запити, які також можуть бути цікаві при просуванні.

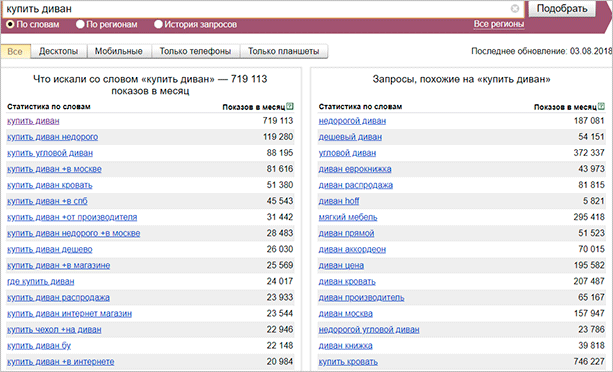
У цій статті за допомогою Вордстата ми будемо збирати первинні ключі, які знадобляться нам для подальшого збору семантичного ядра. Але про це пізніше, а поки я наведу вам ще декілька способів, за допомогою яких можна зібрати семантику.
Яндекс Вордстат + СловоЕБ
Програма з таким барвистим назвою є абсолютно безкоштовним аналогом Key Collector. Природно і функціоналу в ньому трохи менше, ніж у комерційному конкурента, але для збору семантичного ядра під пошукове просування цього цілком вистачить.
Якщо вам цікаво, чим СловоЕБ відрізняється від Кей Колектора, просто гляньте на цю табличку.

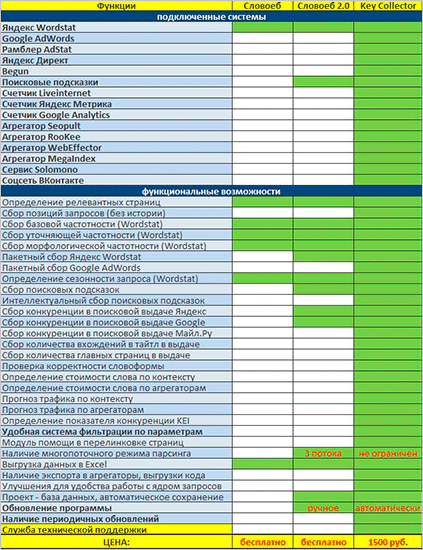
Безумовно, відмінностей тут вагон і маленький візок. Однак для простого збору ядра можливостей СловоЕБа цілком вистачить.
Онлайн-сервіси
Отже, крім вищеописаних варіантів, семантику можна зробити за допомогою онлайн-сервісів. Якщо ви заб’єте запит “Збір семантики онлайн”, то пошуковик видасть вам велику кількість всіляких онлайн-інструментів. Вони можуть бути як хорошими, так і поганими. І, відповідно, як платними, так і безкоштовними.
З допомогою різних онлайн-сервісів можна ще дізнатися семантичне ядро конкурентів. Будьте впевнені, що практично всі компанії займаються перевіркою даних своїх потенційних суперників.
Замовлення у фахівця
Ви можете просто купити готове рішення у фахівця. Він все зробить, і на виході ви отримаєте цілісний файлик з усіма запитами. Далі з нього вже можна буде створити список статей з технічними завданнями до них. Ну і віддати це все на поталу копірайтерам. Але це вже питання делегування обов’язків, його сьогодні зачіпати ми не будемо.
Варто складати семантику?
Якщо ви відкрили цю статтю, то вас, безумовно, цікавить і це питання теж. Збір семантики здається спочатку дуже тужно і важким справою. Причому користувачі не завжди розуміють, навіщо це взагалі потрібно.
Якщо ми говоримо про блозі, причому створеному з метою заробітку, то у авторів таких проектів виникає цілком резонне питання: де, власне, брати натхнення і про що взагалі писати. Якщо у вас буде готова таблиця зі всіма темами і ключовими словами, то ви точно будете знати, про що написати свій матеріал. Такий підхід дозволить не тільки не збавляти темпу, але навіть і збільшити, тому вам не доведеться ламати голову над темою чергової статті. Залишиться тільки вибрати із запропонованого списку і вирішити для себе, як саме написати той чи інший матеріал.
Разом з цим всі ваші статті (за умови грамотного написання текстів і дотримання частотності ключів) будуть непогано вилітати в топ пошукових запитів, що забезпечить вам відвідуваність, і це ще більше підігрівати інтерес і мотивувати на нові звершення. Цікаво ж, правда? І все це завдяки одному єдиному елементу – семантиці, збір якої у вас не займе багато часу.
Якщо ж мова йде про комерційних сайтах (лендінгем, інтернет-магазини тощо), то збір семантичного ядра просто обов’язковий. От серйозно, без цього взагалі ніяк. Семантика нам знадобиться як при наповненні ресурсу контентом і мета-тегів, так і для контекстної реклами, через яку ми будемо просувати бізнес.
Для збору семантики під контекст одного СловоЕБа буде мало. Доведеться купувати його розширену версію, іменовану Кей Колектором. Програма має велику кількість різних опцій, призначених саме для роботи з різними контекстними мережами (Директ, Адвордс і т. д.)
Підводячи підсумок, приходимо до висновку, що складати семантику безперечно варто. Це підвищує якість просування вашого ресурсу і дозволяє на порядок краще орієнтуватися в потребах користувачів при складанні контент-плану.
Як правильно скласти семантичне ядро по кроках?
При підборі СЯ ми постараємося вкластися в п’ять кроків. Вони будуть включати в себе: пошук і підбір первинних ключових слів, парсинг їх у програмі СловоЕБ або Кей Колектор (сам буду використовувати перший варіант), визначення частотності для кожного запиту, кластеризація і збір хвостів, тобто додаткових слів, які містяться в пошуковому запиті.
Наприклад: купити дивани чорного кольору в Краснодарі онлайн, де жирним виділено наш ключ, а все що далі – хвіст. Якщо в наших статтях будуть присутні не тільки основні запити, але і хвости до них, то цілком ймовірно, що ці матеріали будуть збирати відвідувачів з більшої кількості різних варіацій цих фраз.
Що ж, давайте почнемо складати семантику по кроках.
Збір первинних ключів
Для збору первинних слів і фраз ми будемо використовувати Вордстат. Але перед цим нам потрібно самостійно придумати, на які теми ми будемо писати статті або ж здійснювати просування, якщо мова йде про комерційне типі сайтів. Для себе я випишу такі теми рубрик:
- заробіток,
- фінанси,
- фріланс,
- копірайтинг,
- партнерки.
Думаю, що для прикладу 5 штук буде достатньо. У вашому випадку цих тем може бути більше. При виборі первинних ключів для блогу можна використовувати назви рубрик, за якими в подальшому буде здійснюватися написання текстів.
Тепер ми беремо перше слово і забиваємо його в Вордстат. Сервіс видає нам велику кількість різних запитів з їх частотністю, тобто кількістю звернень конкретно з такими словами в пошуковик Яндекс. Ось так це виглядає.

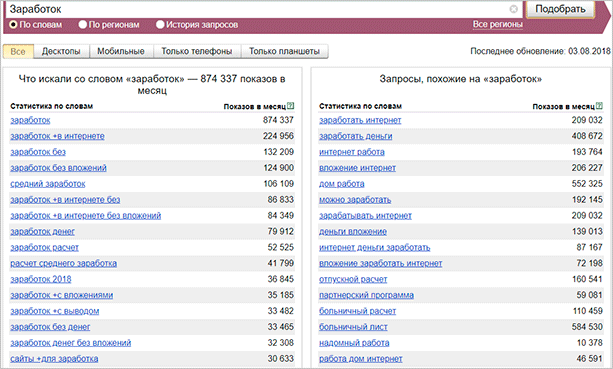
Як бачите, варіантів тут предостатньо. Сервіс видав нам найбільш популярні запити зі словом заробіток. В правій же частині він показав схожі варіанти, які можуть нам сподобатися.
Здавалося б, можна на цьому зупинитися. Просто написати статті з використанням ключів кшталт “заробіток в інтернеті” або “заробіток без вкладень” і чекати, коли десятки тисяч користувачів кинуться читати наш шедевр.
Але не все так просто, тут представлені тільки високочастотні ключові фрази, просуваючись по яких у нас не буде шансу потрапити і в першу сотню сайтів. Викидати їх у смітник теж не варто, саме ефективне просування полягає в раціональному використанні всіх типів ключових слів і словосполучень.
Тепер ми проробляємо те ж саме по всім представленим первинним словами. А потім ще й по найбільш популярних варіацій, наданими самим сервісом.
Після першого кроку у нас на руках повинен бути список з декількох десятків самих смачних, на нашу думку і на думку Вордстата, запитів. Намагайтеся вибирати найбільш людські і правильні з точки зору складання запити. Я думаю, що проблем з цим виникнути не повинно.
Виглядати це має приблизно так.


Парсинг базових запитів за допомогою СловоЕБа/Кей Колектора
Тепер ми переходимо до найцікавішого. З допомогою СловоЕБа або Кей Колектора ми повинні спарс всі базові запити, зробивши з них об’ємну сітку з самих різних варіацій. Інакше кажучи, нам потрібно отримати всі запити, які включають в себе такі фрази або слова.
Створюємо новий проект, використовуючи кнопку в головному вікні або в верхньому меню.

Після того, як проект створений, потрібно почати збір семантики через Wordstat. Грубо кажучи, програма сама підключиться до Вордстату і збере звідти всі необхідні дані. Для цього нам знадобиться зареєструвати новий аккаунт Яндекса, щоб було не шкода, якщо його забанять, і вписати його дані в налаштуваннях. Зробити це неважко, тим більше, що утиліта сама видає підказки.

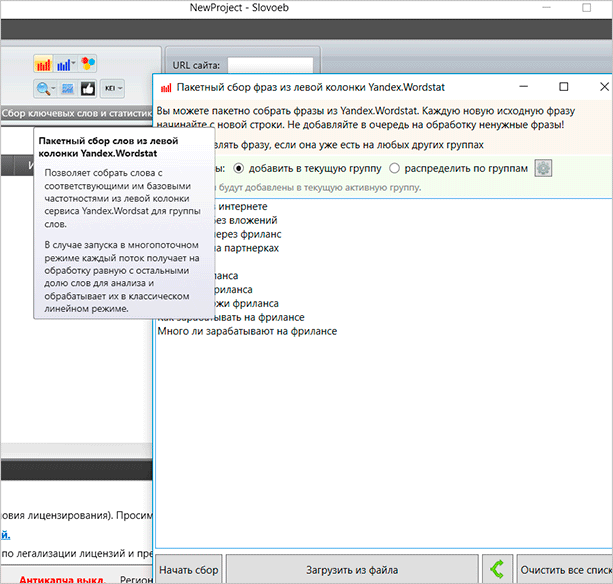
Зверніть увагу, що для збору ми використовуємо ліву колонку Вордстата. В ній будуть всі пошукові запити, які містять цей ключ в прямому входження. Але ми також можемо використовувати і інший варіант – збір з правої колонки, де є “схожі” слова і фрази. Таким чином ми можемо скласти велику кількість різносортних пошукових запитів, отримавши, до всього іншого, ще й схожі.
Отже, вводимо всі ключі в поле вискочив вікна і після цього натискаємо на кнопку “Почати збір”.
Процес запуститься, і програма почне пошук запитів з вмістом потрібних фраз. Само собою, чим більше буде цих самих фраз, тим більше буде запитів на виході. Для прикладу я залишив один запит “Заробіток в інтернеті”, після чого запустив процес. Ось такі дані мені видала програма.

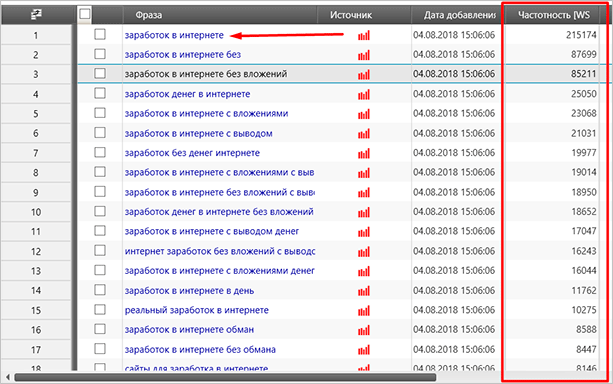
Як бачите, зі своїм завданням вона впоралася, а я отримав не тільки різносортні запити, але і їх частотність. Однак не поспішайте радіти. Дані, які я обвів червоним прямокутником, можуть бути й зовсім непотрібними або неправильними. Таке явище ще називають брудна або базова частотність.
Якщо ви будете орієнтуватися на базову частотність, то цілком можливо, що статті, складені з урахуванням, здавалося б, популярних запитів, не отримають ні одного кліка за кілька місяців. З цієї причини ми повинні отримати справжні дані, для цього ми скористаємося внутрішнім функціоналом цієї програми.
Отримання цієї частотності
Для отримання цієї частотності ключових слів і фраз ми можемо скористатися вбудованим функціоналом СловоЕБа або Кей Колектора. Т. к. в цій статті ми розглядаємо роботу саме з першої утилітою, я поясню все саме на її прикладі. В Key Collector цей процес майже нічим не відрізняється. Можливо, що в нових версіях змінилося розташування елементів.
Але я впевнений, що ви розберетеся. У СловоЕБе ж ми просто знаходимо ось такі кнопки.

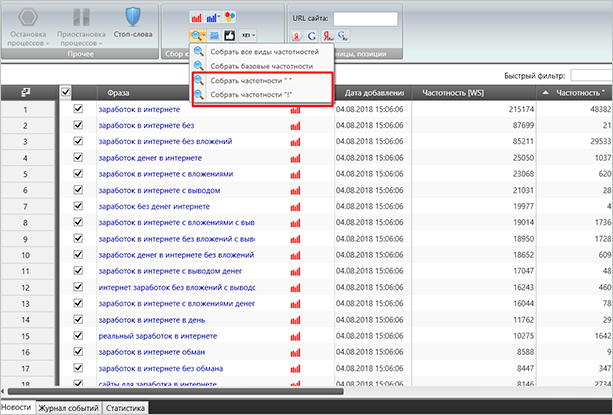
Частотність “ “ – входження тільки слів, які знаходяться в лапках. Закінчення та порядок можуть бути різними.
Частотність ! – точне входження ключа з фіксованим закінченням і порядком слів.
Чистка запитів дозволить отримати достовірні дані по частоті запитів, що надходять від користувачів Яндекса. Різницю між двома стовпцями ви можете бачити на власні очі. У ключі “заробіток в інтернеті” чиста частота запитів майже в 5 разів менше. В інших словах вона може бути ще більш відчутною, тому обов’язково після кожного збору семантики користуйтеся інструментами для виявлення більш правильних показників.
Коли процес складання правильних даних буде завершений, ви можете скористатися швидким фільтром (з регулярними виразами) для пошуку і видалення зайвих запитів. Або ви можете зробити це вручну, просто прокрутивши повзунок і знайшовши всі варіанти, які не відповідають якогось певного порогу.
В цьому випадку я рекомендую звертати увагу на запити, які можуть принести нам трафік. Але не намагайтеся лізти відразу в високочастотні ключі, які, як правило, використовує дуже величезна кількість більш розкручених сайтів.
Конкурентність всіх запропонованих запитів ми, звичайно, перевіримо далі. Однак їжаку зрозуміло, що якщо частота запиту становить кілька десятків тисяч, то і конкурентів там буде дуже багато.
Треба виходити з міркувань раціоналізму, про що я вже говорив вище. Вибирайте ключі, за якими не надто багато запитів. Непопулярні відстійники, з частотою півтора запиту в місяць нам теж не потрібні.
Кластеризація запитів
Тепер нам належить розділити все наше семантичне ядро, а вірніше ключі, які в ньому містяться, на групи. Кластеризовать, в рамках цього матеріалу, я буду якраз по частотності. Це найбільш популярний варіант, який використовується майже повсюдно.
Всі слова і фрази ми можемо розділити на високочастотні, середньочастотні, низькочастотні і микронизкочастотные. Пояснювати, за яким принципом відбувається групування, думаю, не потрібно. Однак, окреслити приблизні діапазони необхідно.
Відразу скажу, що скільки людей, стільки й думок. Іноді вони розходяться, вважати мій варіант за абсолютну істину не варто. Цілком можливо, що в інших фахівців значення будуть відрізнятися в більшу або меншу сторону.
- ВЧ – понад 10 000 запитів на місяць;
- СЧ – від 1 000 до 10 000;
- НЧ – до 1 000;
- МНЧ – менше 100.
Цифри вкрай суб’єктивні і примерны, взяті із загальноприйнятих даних, які я коли-то отримав досвідченим шляхом. Але варто сказати, що цей варіант я бачив часто.
Принцип кластеризації по частоті буде виглядати як розбивка всіх запитів по групах, виходячи з кількості пошукових звернень користувачів. Їх ми вже отримали на попередньому кроці, тепер нам залишається розподілити запити по цим групам.
Тут же можна ввести ще кілька груп, виходячи не з частотності запитів, а з конкурентності, тобто кількості сайтів, які вже здійснюють просування по них.
Є висококонкурентні, среднеконкурентные і низкоконкурентные запити. Ми можемо розгрупувати всі дані і за такого типу, що навіть буде краще. Для більш ефективного просування нашого сайту ми повинні підібрати запити з найбільшою частотою і найменшою конкуренцією. Це, звичайно, в ідеалі.
Для кластеризації запитів можна користуватися як автоматичними інструментами (онлайн-сервіси), так і своїми власними ручками.
Якщо робити це вручну, то можна в прямому сенсі зійти з розуму. І щоб не ламати свою психіку, я б радив вам скористатися автоматичними сервісами для розбивки всіх ключових слів по групах.
Таких сервісів в інтернеті не так багато. Більш-менш хороших ще менше, проте слава про одному з досить прийнятних сервісів для кластеризації семантики ходить по Рунету ось вже який рік. Я кажу про сервіс Мутаген, з допомогою якого ми і будемо відтворювати всі вищеописані дії.
Даний онлайн-інструмент платний, але тут є можливість і безкоштовного використання з деякими обмеженнями. Не більше 10 перевірок на добу.
Проблем з використанням Мутагену бути не повинно. Інтерфейс там інтуїтивно зрозумілий, російською мовою. Там же є невелике ЧаВо, в якому пояснюються основи роботи з цим сервісом.
Тут же скажу, що для більш швидкої кластеризації потрібно користуватися масової перевіркою. Не будемо ж ми тисячі запитів перевіряти по одному. Для цього доведеться зареєструватися на сервісі і тільки після цього розділ масової перевірки стане доступний.
Потім залишиться просто скопіювати всі ключі з СловоЕБа, ну і по завершенню всіх процесів вивчити всі показники конкурентності, а далі і згрупувати їх.
Пошук хвостів
Наостанок ми повинні взяти все найсмачніші ключі, після чого спробувати пошукати хвости. Просто вбиваємо потрібний запит в Яндекс, після чого він видасть їх нам сам.


Як бачите, тут їх не так багато. Здавалося б, навіщо взагалі перевіряти і парсити хвости з запитів. Невже розумний Яндекс сам не закине наш ресурс видачу за запитами з хвостами? Може бути і закине, однак, якщо десь на вашому ресурсі будуть проскакувати матеріали ось з такими хвостами, то набагато більш імовірно саме ваш сайт буде в топі видачі по цим запитам.
Просування з використанням запитів з хвостом особливо актуально для молодих сайтів. Трасту у таких ресурсів немає, а от якщо десь у статті буде ключ в прямому входження, то найімовірніше Яндекс кине в топ навіть ресурс без трасту. Яшу важливо, щоб кожен користувач отримував саме те, навіщо він прийшов в пошуковик. Тому варто користуватися цим і додати в своє семантичне ядро запити з хвостами.
Збирати хвости, на превеликий жаль, доведеться вручну. Але вам не варто намагатися парсити хвости для всіх тисяч ключів. Робіть це вибірково, з урахуванням розуміння того, що може бути дійсно цікаво вашим відвідувачам.
Висновок
Як бачите, зібрати семантичне ядро можна всього за 5 кроків. Звичайно, в цій інструкції представлений базовий варіант, який допоможе вам пізнати ази і зробити найпростішу семантику. Для більш серйозних проектів знадобиться відповідний підхід. Наприклад, при кластеризації ключевіков вам доведеться ділити їх не тільки на ВЧ і НЧ, або ВК і НК, але і на комерційні та некомерційні. Або навіть на групи з урахуванням регіональності.
Все це буде неодмінно займати час, але якщо ви самостійно будете працювати над семантикою, збирати її і бачити, як взагалі йдуть справи на ринку пошукових систем, то через деякий час до вас поступово буде приходити і розуміння. Ви будете знаходити все нові інструменти для різних процесів, зможете робити збір семантики і її угруповання чисто на одному диханні. Звичайно ж, за умови, що вам це буде цікаво.
Якщо ви самі не хочете розбиратися з усім цим, то завжди можна замовити збір семантичного ядра у фрілансера або який-небудь студії. В інтернеті повно різних контор, які готові спарс всі дані і просто надати вам Excel-файлик. Ціна може бути різною. Але я впевнений, що якщо захотіти, то можна знайти хорошого фахівця.До речі кажучи, якщо вам щось незрозуміло з цієї статті і ви ніяк не можете розібратися зі збором семантичного ядра, то повинен повідомити, що на курсі Василя Блінова “Як створити блог” це питання також буде обговорюватися. Можливо вам варто пройти навчання і отримати всі необхідні знання.
До зустрічі в наступному огляді.